Tracking via Active Inertial Sensing
Introduction
Recent progress in tracking, scene representation (3DGS [1], NeRF [2]), and reconstruction (e.g., NeuS/VolSDF [3], [4] and COLMAP [5]) has made geometry and appearance recovery of static scenes gradually mature. A natural next step is dynamic-scene understanding, including physically consistent motion modeling and interaction prediction. Although modern video and motion generation methods are promising, they rarely preserve accurate physical quantities, largely due to limited high-quality training data.
Simulation can partially alleviate data scarcity, but it is still limited in realism and interaction complexity. Dense multi-view capture systems require many calibrated and time-synchronized cameras, resulting in high deployment cost and constrained operating conditions (e.g., controlled indoor environments and marker-heavy workflows). Monocular methods, such as FoundationPose-style [6] 6D tracking, are attractive but fragile under object interactions, where occlusion and visual ambiguity degrade reliability (see Figure 1). These limitations motivate robust and scalable approaches grounded in physical measurements.

A straightforward extension is to introduce additional sensing modalities. IMU-based human motion-capture systems (e.g., Xsens and Noitom) demonstrate key advantages: no line-of-sight requirement, resilience to occlusion, high-frequency measurements, and relatively low-cost mobile hardware. Following this intuition, we investigate whether attaching one IMU to each object enables direct sensing of inter-object dynamics.
Inspired by prior IMU-based trajectory estimation on pedestrians [8], [9], [10] and robotic platforms [11], [12], [13], we formulate object tracking as a motion recovery problem from raw inertial streams (accelerometer and gyroscope). Instead of directly estimating full 6D pose through naive double integration, we prioritize learning stable intermediate motion quantities (e.g., velocity direction) and use them as a foundation for later trajectory reconstruction. Accordingly, this report presents a feasibility study on inertial motion recovery rather than a full 6D pose estimation/tracking system or visual-inertial fusion framework.
Basics About the WitMotion 9-axis IMUs
Throughout this project, we employ WitMotion 9-axis WT901WIFI IMUs. Several sensor characteristics should be clarified before introducing the downstream method.
The WT901WIFI provides stable inertial measurements at 100 Hz, which is adequate for our object-level motion capture setting. However, in most real-world environments we do not rely on the device-provided fused orientation. Its onboard fusion depends on accelerometer, gyroscope, and particularly magnetometer observations. In scenes containing metallic structures and nearby electronic equipment, magnetic disturbances are common and can substantially degrade yaw and overall attitude estimates. Accordingly, unless the environment is magnetically clean (i.e., with minimal metal and electromagnetic interference), the fused orientation output is treated as unreliable.
The Allan variance analysis [14] (shown in Figure 2) reveals clear axis-dependent behavior in the accelerometer: the z-axis exhibits substantially higher noise and greater bias instability than the x- and y-axes. This asymmetry must be considered when designing motion recovery algorithms.
In summary, the WT901WIFI is a practical low-cost IMU (approximately 100 RMB) that provides convenient 100 Hz measurements for dynamic scene data collection. While it does not match the precision of premium devices (e.g., Xsens Movella Dot or Noitom sensors), it offers a favorable cost-performance trade-off for large-scale experimentation.
Problem Formulation and Data Collection Protocol
This report focuses on investigating whether informative velocity cues can be reliably inferred from IMU signals, with an emphasis on velocity direction as a diagnostic intermediate target. To obtain scalable and reproducible training data, we adopt a robot-assisted pipeline. Specifically, an IMU is mounted on the end-effector of an xArm6 using custom 3D-printed fixtures. The robot executes predefined motion programs, enabling collection of inertial sequences with controlled kinematics for model training and evaluation.
At this stage, the central technical question is whether a single low-cost IMU provides sufficient information to infer motion in our setting. Prior studies, such as RoNIN [9] and TartanIMU [11], have demonstrated promising results, but under specific assumptions:
- These methods learn a mapping from a window of inertial data to the average velocity of that window, i.e., \([\boldsymbol{\omega}_{1:t},\mathbf{a}_{1:t}] \rightarrow \bar{\mathbf{v}}\). From a physical perspective, however, integrating acceleration over a finite window yields a velocity increment \(\Delta \mathbf{v}\) rather than an absolute velocity. Some argue that the model learns a data-driven mapping from IMU sequences to velocity that is valid within the distribution of motions seen during training, and this process can be viewed as “locally anchored velocity estimation”.
- Existing benchmark platforms (e.g., pedestrians, legged robots, and mobile robots) often exhibit relatively structured motion statistics, such as quasi-periodic gait patterns. This structural regularity can implicitly support velocity regression, yet the effective motion distribution assumptions are rarely quantified explicitly.
- In contrast, our target setting involves arbitrary object motions, because the IMU may be attached to diverse objects with distinct and non-periodic dynamics. This regime is less explored in prior work. Therefore, instead of directly regressing velocity magnitude and direction jointly, we first study velocity direction classification to improve robustness against sensor noise and bias.
Method and Experiments
This section presents the model design and a staged experimental study. And we have prepared the following self-collected datasets with the xArm6 robot arm:
- AXIS-7 : 7-class axis-aligned motion dataset.
- DIR27-L : 27-class directional dataset, larger split (200 sequences/class).
- DIR27-S : 27-class directional dataset, smaller split (100 sequences/class).
- POLY-27 : 27-class zigzag/polyline motion dataset.
The xArm6 recording procedures for linear and polyline trajectories are shown in Figure 3.


Backbone: iTransformer
IMU windows are multivariate time-series signals. To model temporal dependencies while maintaining Transformer scalability, we build our backbone on iTransformer [15], where time points from each series are embedded as variate tokens. Following RoNIN [9], we additionally use a 1D convolution-based embedding module for raw inertial features and add learnable position encoding on the temporal domain. The full architecture is shown in Figure 4.

We train and evaluate the model on the public RoNIN dataset [9] as a proof-of-capability benchmark. RoNIN contains large-scale human inertial trajectories, and this stage is intended to verify whether the proposed architecture can learn meaningful motion information from IMU streams. We compare against representative baselines and report absolute trajectory error (ATE) and relative trajectory error (RTE) in meters (lower is better). This benchmark is independent of our robot-collected datasets; unless stated otherwise, all experiments below are trained and evaluated on our self-collected data only.
| RONIN-ResNet [9] | CTIN [16] | iMoT [17] | DiffusionIMU [18] | M2EIT [19] | Ours | |
|---|---|---|---|---|---|---|
| Seen ATE/RTE | 3.70/2.78 | 4.62/2.81 | 3.78/2.68 | 3.64/2.72 | 3.58/2.76 | 3.80/2.75 |
| Unseen ATE/RTE | 5.48/4.56 | 5.61/4.48 | 5.31/4.39 | 5.27/4.31 | 5.19/4.57 | 5.47/4.61 |
Although the proposed model does not yet achieve state-of-the-art performance, the results indicate competitive accuracy and, more importantly, validate the feasibility of our design. We emphasize that this benchmark is used as a proof-of-capability study; exhaustive hyperparameter tuning was intentionally not performed at this stage.
Problem Formulation: Velocity Direction Classification
Rather than directly regressing continuous velocity vectors, we formulate the problem as a classification task over discretized motion directions. Given a temporal window of IMU measurements consisting of angular velocity \(\boldsymbol{\omega}_{k:k+W}\) and linear acceleration \(\mathbf{a}_{k:k+W}\) (where \(W=100\) frames), we aim to learn a mapping: \(\mathcal{F}: [\boldsymbol{\omega}_{k:k+W}, \mathbf{a}_{k:k+W}] \rightarrow c \in \mathcal{C}\) where \(c\) is a discrete direction class and \(\mathcal{C}\) is the set of predefined directional bins.
This classification-based approach offers several advantages: (1) it provides interpretable motion primitives, (2) it reduces sensitivity to velocity magnitude variations, and (3) it enables systematic evaluation of model generalization across motion complexity levels. We design a progressive experimental protocol with three phases of increasing complexity.
Phase 1: Axis-Aligned Motion Classification
Objective. We begin with the simplest motion scenario: straight-line translations along the three principal body axes. The task is to classify 7 motion primitives: positive and negative directions along \(x\), \(y\), and \(z\) axes, plus a static (no-motion) class.
Dataset characteristics. The AXIS-7 dataset contains approximately 500 sequences for each class (~5 hours total). To diversify conditions, we apply diverse initial rotations before each motion segment: both rotations around x-axis (in-plane) and rotation around the z-axis (out-of-plane) rotations are randomized, while orientation remains fixed during each segment. Since direction labels are defined in the body frame, this primarily perturbs the gravity projection and other orientation-dependent artifacts in the raw IMU streams, providing a sanity check on gravity compensation and robustness to such effects.
Preprocessing pipeline. Raw IMU streams are segmented into consecutive fixed 100-frame windows. Each window contains body-frame angular velocity and linear acceleration. A critical preprocessing step is gravity compensation: leveraging the fixed IMU-to-gripper alignment (assumed from the fixture design) and assuming a level robot base, we compute the gravity vector in the body frame via forward kinematics and subtract it from raw acceleration measurements.
Results. The model achieves 95.82% accuracy and 0.9581 weighted F1-score on the held-out test set. The confusion matrix shows the dominant residual errors occur between opposite directions on the same axis, with the most prominent confusion on the \(\pm z\) axis (i.e., \(+z\) vs. \(-z\)), while other classes are largely well separated.
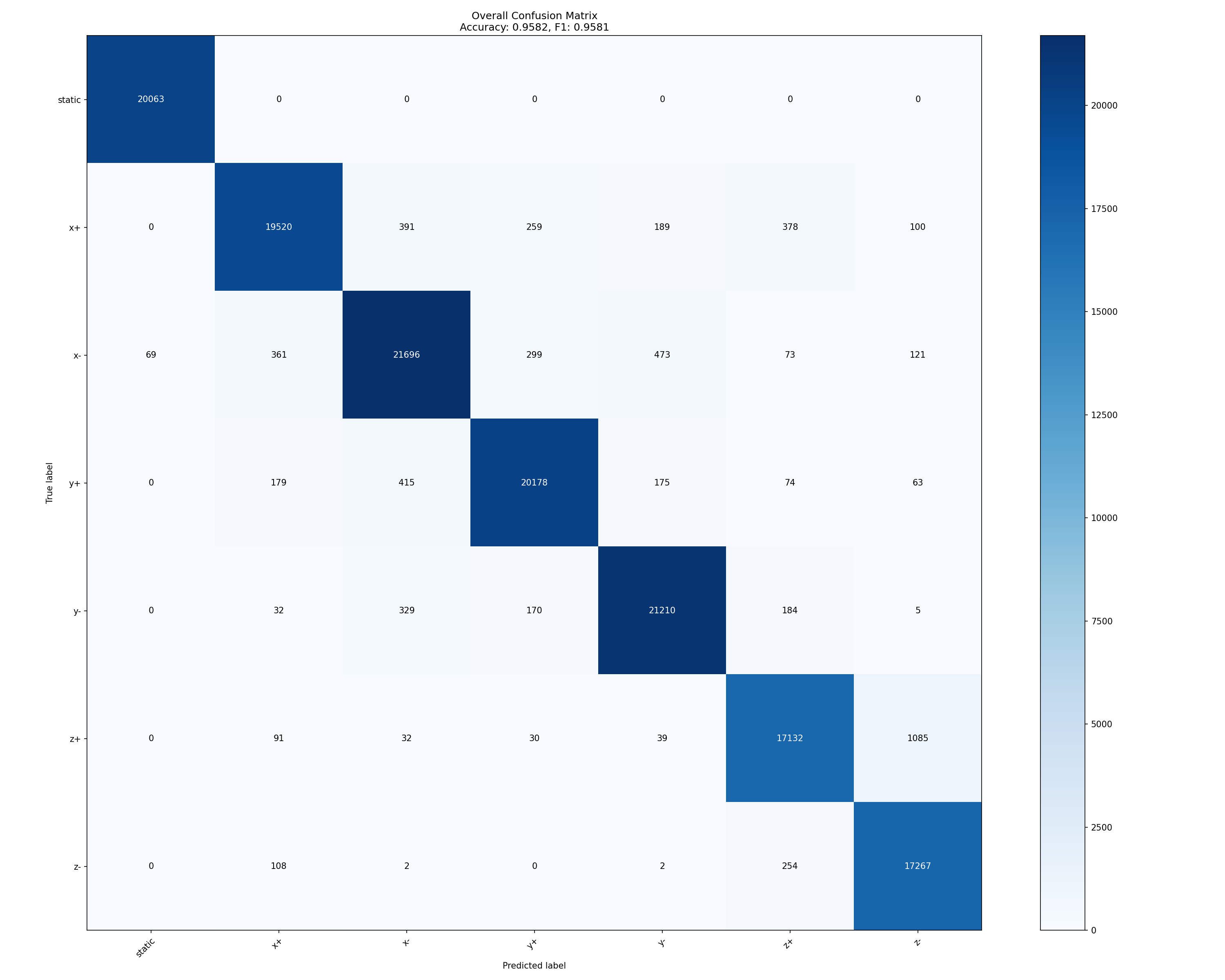
Phase 2: Multi-Directional Motion and Generalization Analysis
Objective. We expand the label space to 27 directions by quantizing each velocity component as \(\{-1, 0, 1\}\), yielding all combinations \((v_x, v_y, v_z) \in \{-1,0,1\}^3\). This setting tests the model’s ability to distinguish fine-grained directional differences.
Dataset characteristics. We collect two datasets under identical protocols: DIR27-L (200 sequences/class, ~7.5 hours) and DIR27-S (100 sequences/class, ~4 hours). Both incorporate the same orientation augmentation strategy as Phase 1. The dual-dataset design enables systematic evaluation of cross-dataset generalization.
Intra-dataset performance. When training and testing on the same dataset (80/20 split), the model achieves 92.23% and 88.84% accuracy on DIR27-L and DIR27-S, respectively. Training on the merged dataset (DIR27-L + DIR27-S) yields an accuracy of 91.84%, indicating that the model can effectively learn the 27-way classification when train and test distributions are matched.
Cross-dataset generalization failure. However, cross-dataset evaluation reveals a severe generalization gap:
- Training on DIR27-L and testing on DIR27-S: accuracy drops to 58.16%.
- Training on DIR27-S and testing on DIR27-L: accuracy drops to 53.38%.
Figure 6 visualizes the confusion patterns for both transfer directions. Notably, the error structures are qualitatively similar, suggesting that the generalization failure is not due to one “bad” dataset split, but rather reflects fundamental distribution mismatch and insufficient statistical coverage. We hypothesize that the model may rely on dataset-specific artifacts (e.g., subtle differences in robot controller dynamics, sensor mounting variations, or environmental factors) rather than learning robust physical motion features.
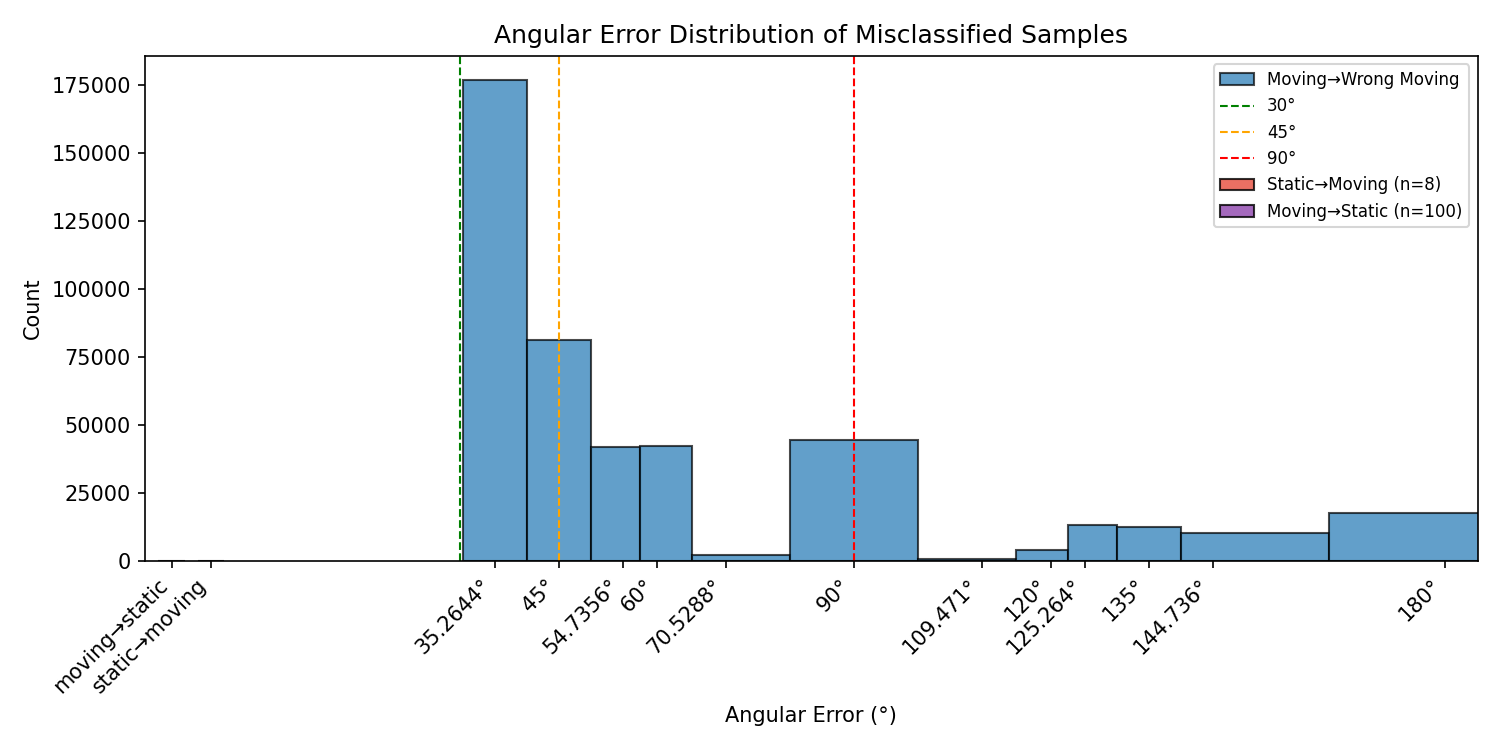
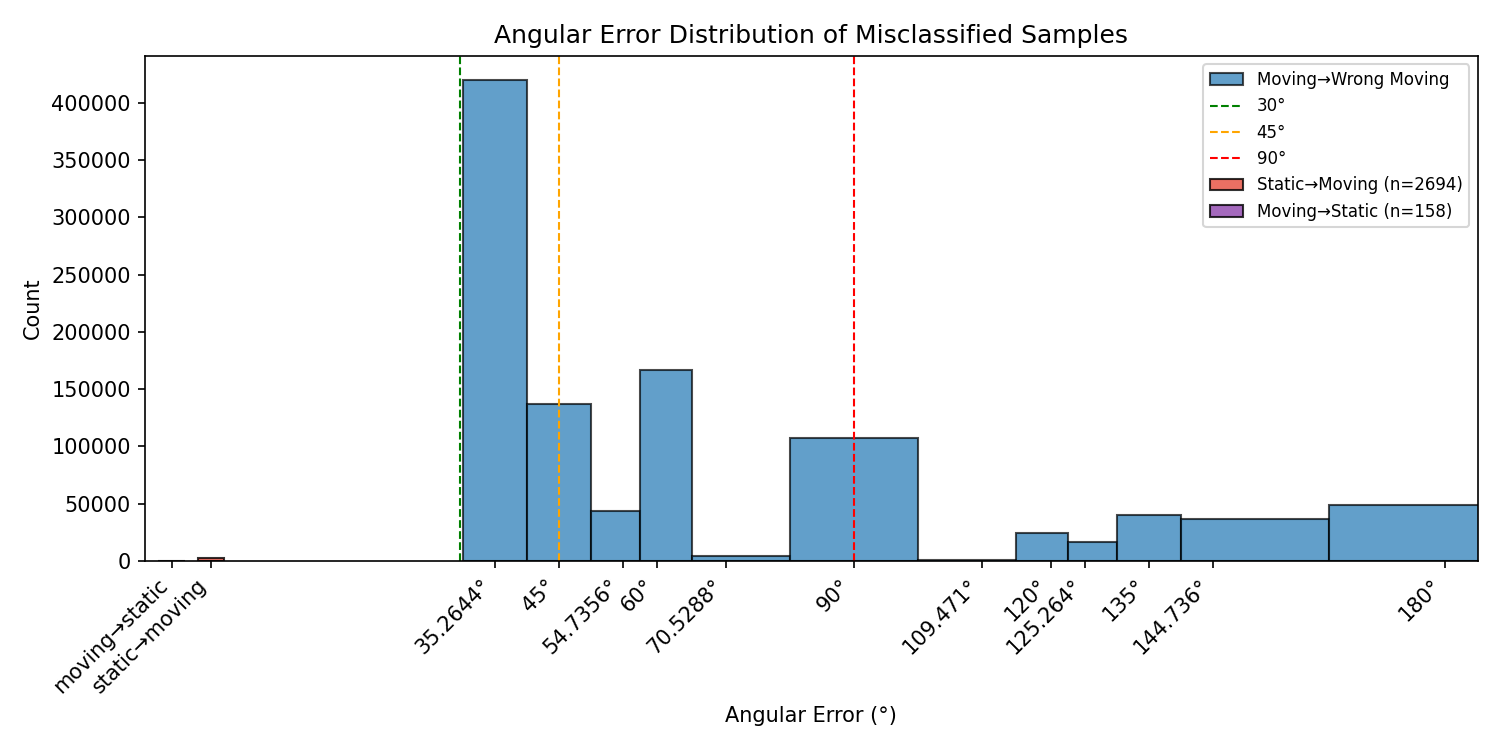
Rotation-equivariant augmentation failure. To probe this failure mode, we evaluate a rotation-equivariant augmentation strategy inspired by RIO [20]. The principle is that rotated inertial inputs should correspond to rotated velocity labels, i.e., \(\left([\boldsymbol{\omega}_{k:k+100},\mathbf{a}_{k:k+100}],\bar{\mathbf{v}}\right)\) and \(\left([\mathbf{R}\boldsymbol{\omega}_{k:k+100},\mathbf{R}\mathbf{a}_{k:k+100}],\mathbf{R}\bar{\mathbf{v}}\right)\) should be equivalent training samples.
In our setting, this augmentation degrades performance rather than improving it. A likely explanation is that practical non-idealities (e.g., axis-dependent sensor bias and controller-induced dynamics in xArm6 velocity execution) violate strict rotational equivalence. As an additional diagnostic, we perform a label-flip test on AXIS-7 by swapping the \(+y/-y\) labels at evaluation time; the F1 score on the y-axis classes drops by 24.7%, supporting the claim that the measured data distribution cannot be modeled as a simple rigid rotation of idealized inertial signals.
Phase 3: Polyline (Zigzag) Trajectory Evaluation
Objective. To better approximate real trajectories with direction changes, we introduce waypoint-driven polyline motions. The IMU orientation remains fixed during each sequence, while instantaneous velocity direction changes over time.
Dataset characteristics. We collect the POLY-27 dataset with 200 sequences/class following zigzag trajectories. Motion commands are executed through the xArm6 Cartesian velocity control API.
Supervision strategy. Because motion within one window is no longer strictly linear, we define the target as the net displacement vector from the first to the last frame in the window: \(\mathbf{d}_{\text{net}} = \mathbf{p}_{k+W} - \mathbf{p}_k\) We then map this net displacement to the nearest class among the 27 directional bins by computing: \(c^* = \arg\min_{c \in \mathcal{C}} \|\text{normalize}(\mathbf{d}_{\text{net}}) - \mathbf{v}_c\|_2\) where \(\mathbf{v}_c\) is the unit direction vector for class \(c\).
Results and analysis. Test accuracy drops to 49.2%, far below the straight-line setting in Phases 1–2 (though still above random chance, 3.7% for 27 classes). This substantial performance degradation indicates that the single-label-per-window assumption becomes invalid when trajectories contain direction changes. In particular, the model trained on straight-line motions does not generalize to windows where the instantaneous velocity varies within the temporal window.
This failure highlights a critical limitation of the classification-based formulation: it assumes motion homogeneity within each window. For realistic trajectories with frequent direction changes, alternative approaches are needed, such as sequence-to-sequence modeling, multi-scale temporal modeling, or regression-based formulation.
Conclusion
Axis-aligned experiments show that velocity-direction classification is feasible for constrained straight-line motions with controlled orientation and accurate gravity compensation (95.82% accuracy on AXIS-7). However, three observations indicate limited robustness for unconstrained object dynamics: (1) a large cross-dataset generalization gap in DIR27 transfer (58.16% and 53.38% accuracy for DIR27-L→DIR27-S and DIR27-S→DIR27-L), (2) failure of rotation-equivariant augmentation under real sensor and control non-idealities (a 24.7% y-axis F1-score drop in a diagnostic label-flip test), and (3) substantial performance degradation on polyline trajectories where a single window label is insufficient (49.2% accuracy on POLY-27).
Overall, these findings suggest that discrete velocity-direction classification serves as a useful diagnostic intermediate target but is not a sufficiently stable endpoint for practical inertial object tracking. Future work should explore alternative supervision strategies (e.g., dense per-frame direction prediction or sequence-to-sequence velocity modeling), integration with visual observations, or physics-informed learning constraints. Due to practical constraints, we conclude this stage of the project with the hope that these insights will inform subsequent research in inertial-based dynamic scene understanding.
References
- [1]B. Kerbl, G. Kopanas, T. Leimkuehler, and G. Drettakis, “3D Gaussian Splatting for Real-Time Radiance Field Rendering,” ACM Trans. Graph., vol. 42, no. 4, July 2023, doi: 10.1145/3592433.
- [2]B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, and R. Ng, “NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis,” in ECCV, 2020.
- [3]P. Wang, L. Liu, Y. Liu, C. Theobalt, T. Komura, and W. Wang, “NeuS: Learning Neural Implicit Surfaces by Volume Rendering for Multi-view Reconstruction,” arXiv preprint arXiv:2106.10689, 2021.
- [4]L. Yariv, J. Gu, Y. Kasten, and Y. Lipman, “Volume rendering of neural implicit surfaces,” in Thirty-Fifth Conference on Neural Information Processing Systems, 2021.
- [5]J. L. Schönberger and J.-M. Frahm, “Structure-from-Motion Revisited,” in Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
- [6]“FoundationPose: Unified 6D Pose Estimation and Tracking of Novel Objects,” in CVPR, 2024.
- [7]N. Carion et al., “SAM 3: Segment Anything with Concepts.” 2025. Available at: https://arxiv.org/abs/2511.16719
- [8]C. Chen, X. Lu, A. Markham, and N. Trigoni, “IONet: learning to cure the curse of drift in inertial odometry,” in Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence and Thirtieth Innovative Applications of Artificial Intelligence Conference and Eighth AAAI Symposium on Educational Advances in Artificial Intelligence, in AAAI’18/IAAI’18/EAAI’18. AAAI Press, 2018.
- [9]S. Herath, H. Yan, and Y. Furukawa, “RoNIN: Robust Neural Inertial Navigation in the Wild: Benchmark, Evaluations, & New Methods,” in 2020 IEEE International Conference on Robotics and Automation (ICRA), 2020, pp. 3146–3152. doi: 10.1109/ICRA40945.2020.9196860.
- [10]B. Rao, E. Kazemi, Y. Ding, D. M. Shila, F. M. Tucker, and L. Wang, “CTIN: Robust contextual transformer network for inertial navigation,” in Proceedings of the AAAI Conference on Artificial Intelligence, 2022, pp. 5413–5421.
- [11]S. Zhao, S. Zhou, R. Blanchard, Y. Qiu, W. Wang, and S. Scherer, “Tartan IMU: A Light Foundation Model for Inertial Positioning in Robotics,” in Proceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 22520–22529.
- [12]Y. Qiu, C. Xu, Y. Chen, S. Zhao, J. Geng, and S. Scherer, “AirIO: Learning Inertial Odometry With Enhanced IMU Feature Observability,” IEEE Robotics and Automation Letters, vol. 10, no. 9, pp. 9368–9375, 2025, doi: 10.1109/LRA.2025.3581130.
- [13]C. Luo, Y. Wang, W. Cai, and M. Zhao, “AutoOdom: Learning Auto-regressive Proprioceptive Odometry for Legged Locomotion.” 2025. Available at: https://arxiv.org/abs/2511.18857
- [14]R. Buchanan, Allan Variance ROS. (November 2021). Oxford Robotics Institute, DRS Lab. Available at: https://github.com/ori-drs/allan_variance_ros
- [15]Y. Liu et al., “iTransformer: Inverted Transformers Are Effective for Time Series Forecasting,” in The Twelfth International Conference on Learning Representations, 2024. Available at: https://openreview.net/forum?id=JePfAI8fah
- [16]B. Rao, E. Kazemi, Y. Ding, D. M. Shila, F. M. Tucker, and L. Wang, “CTIN: Robust contextual transformer network for inertial navigation,” in Proceedings of the AAAI Conference on Artificial Intelligence, 2022, pp. 5413–5421.
- [17]S. M. Nguyen, D. V. Le, and P. Havinga, “imot: Inertial motion transformer for inertial navigation,” in Proceedings of the AAAI Conference on Artificial Intelligence, 2025, pp. 6209–6217.
- [18]X. Teng et al., “DiffusionIMU: Diffusion-Based Inertial Navigation with Iterative Motion Refinement,” in Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, IJCAI-25, J. Kwok, Ed., International Joint Conferences on Artificial Intelligence Organization, Aug. 2025, pp. 8787–8795. doi: 10.24963/ijcai.2025/977.
- [19]Y. Li et al., “M2EIT: Multi-Domain Mixture of Experts for Robust Neural Inertial Tracking,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Oct. 2025, pp. 28207–28216.
- [20]X. Cao, C. Zhou, D. Zeng, and Y. Wang, “RIO: Rotation-Equivariance Supervised Learning of Robust Inertial Odometry,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2022, pp. 6614–6623.